はじめに
こんにちは!スタイル・エッジLABOのSです。 今回は最近の私の相棒であるRainbow CSVについてご紹介させていただきます。
よくVisual Studio Codeおすすめの拡張機能として取り上げられるこちらの拡張機能ですが、 恥ずかしながら私、つい最近まで「CSVを見やすく色付けしてくれるプラグイン」くらいにしか思っていませんでした。
最近CSVのようなテキストデータを取り扱う機会が多くなり、 軽くて楽に扱えるエディタ(もしくはビューワー)はないものかと探していたところ…
あれ?これもしかして…使える?
ということで、あらためてRainbow CSVの公式サイトを読んで使ってみました。
Rainbow CSV
今回ご紹介させていただくのはVisual Studio Codeの拡張機能ですが、 Rainbow CSVのプラグインは、Atom、Sublime Text、Vimなどに対応したものもあります。 お使いのエディタに合わせたプラグインをご利用ください。
なお、本稿ではサンプルデータとして、日本政府が公表している国勢調査のCSVを用いています。
利点1:CSVが見やすい
カラムごとに色をつけてくれるだけでもずいぶんデータが見やすくなりますが、 同じようなデータが並んでいたりすると、「あれ?これ何の項目だっけ?」とヘッダを確認したり、カンマの数を数えたり、、、
そんな不毛な作業とはこれでさようなら!
ヘッダレコードを含むCSVであれば、マウスオーバーでヘッダテキストを表示してくれます!
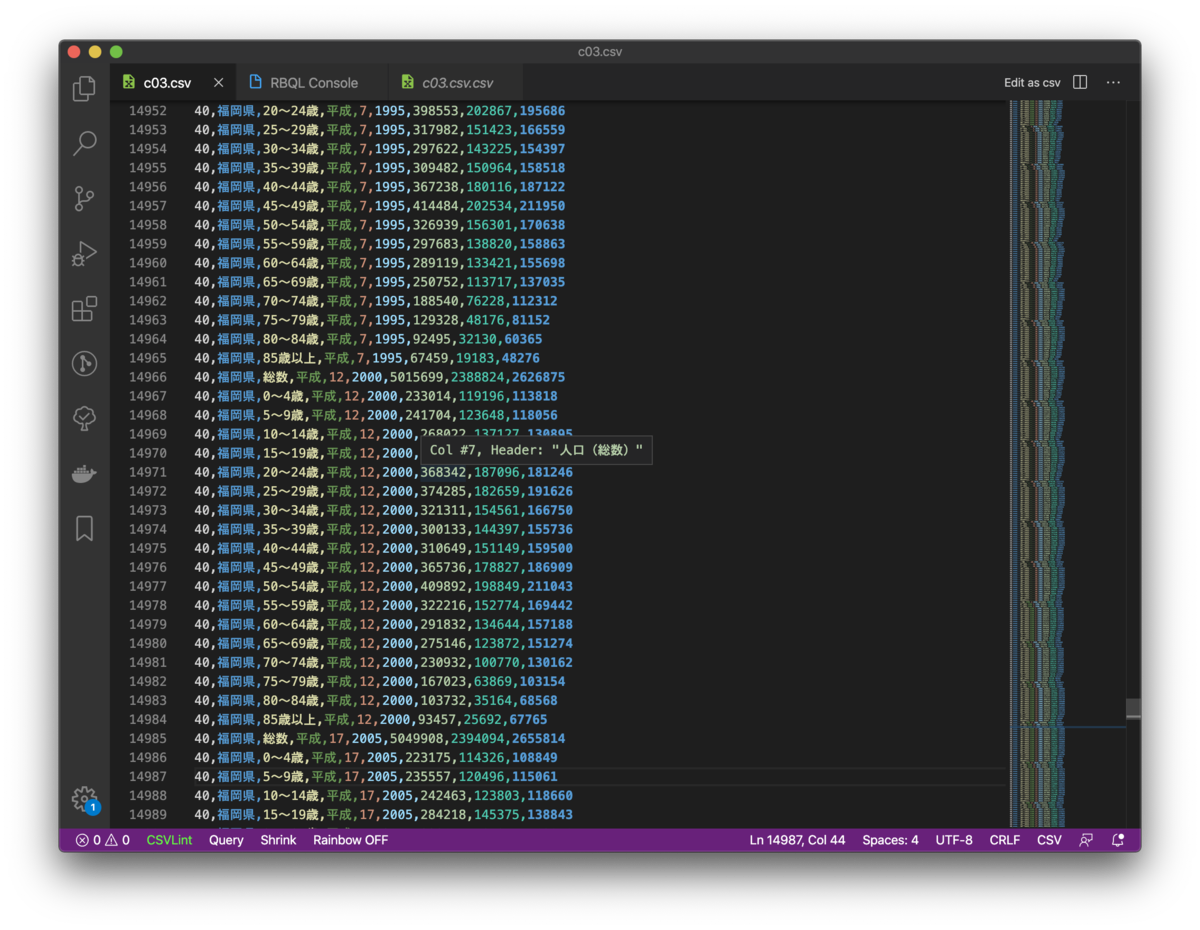
でも、ヘッダレコードを含んでいないCSVもありますよね。
そんな時は仮想のヘッダを定義することができます。
コマンドパレットを開いて「Rainbow CSV: Set Virtual Header」を選択します。
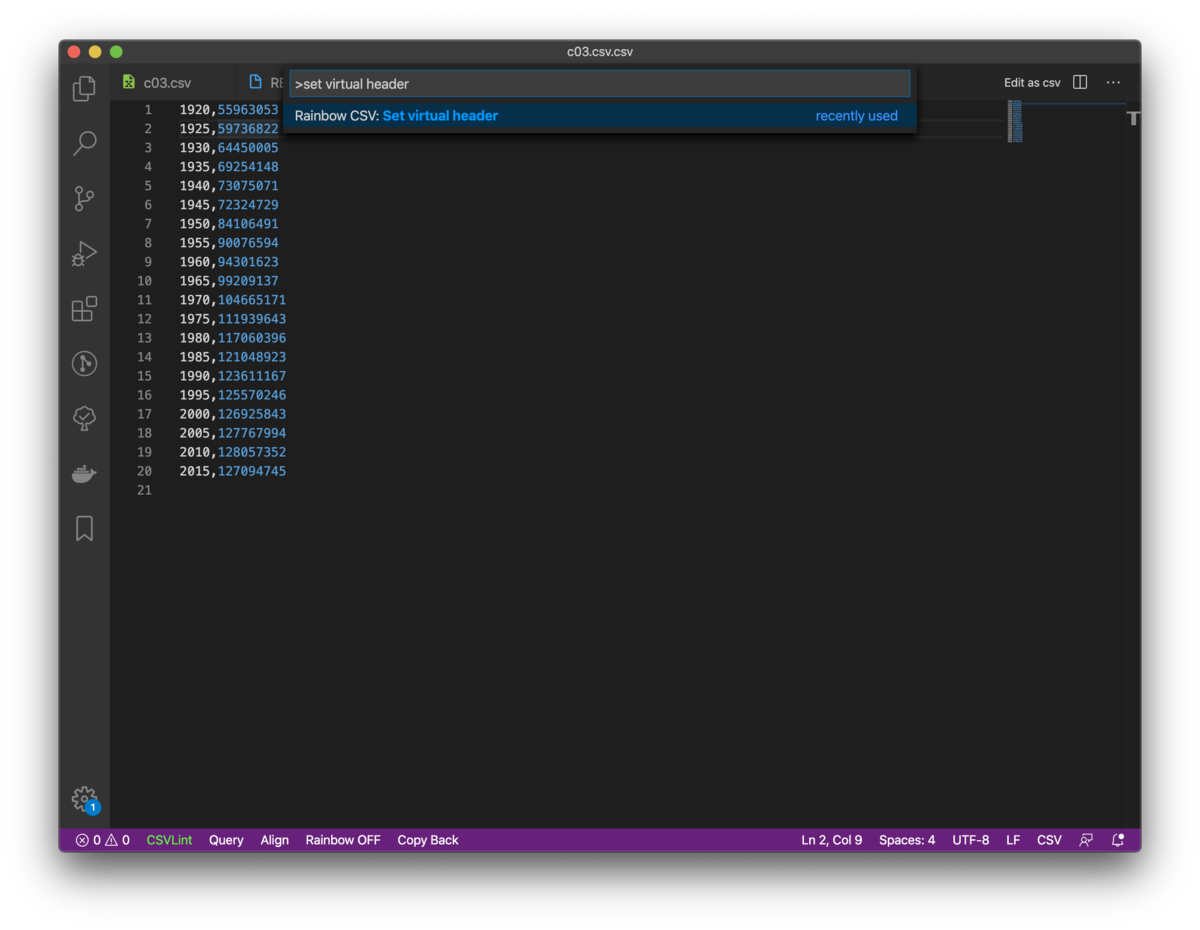
カンマ区切りで、ヘッダとして設定したい文字列を入力します。

そうすると、先ほどと同じように、マウスオーバーでヘッダテキストを表示してくれるようになります。

半角データのみのファイルであれば、align機能も便利です。
ただし、元のファイルに変更が加えられてしまうため、誤って保存しないように注意が必要です。
align機能を使うには、先ほどと同様にコマンドパレットを開いて「Rainbow CSV: Align CSV Columns」を選択します。
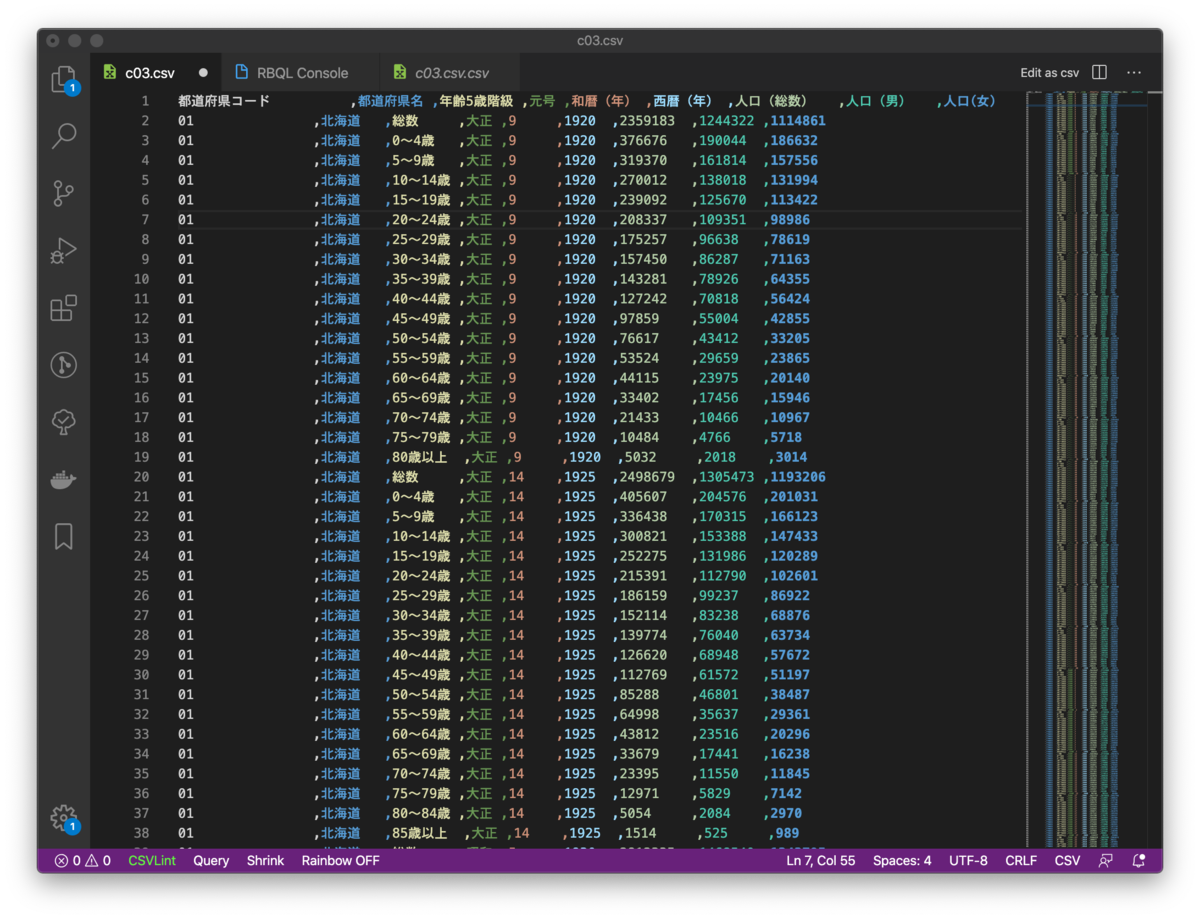
データの文字数に応じて半角スペースでパディングされるようで、残念ながら全角を含んでいると少しずつずれてしまいますが、この程度であれば十分に見やすくなりますね。
利点2:カラムの全選択ができる
コマンドパレットを開いて「Rainbow CSV: Column edit select」を選択します。
すると、すべてのレコードに対して、いまキャレットの置かれているカラムを選択状態にしてくれます。

しかし(本当に)残念ながら10000行以上のデータではこの機能は使えません。
Multicursor column edit works only for files smaller than 10000 lines.
利点3:RBQLが使える
RBQLというSQLに似たクエリを用いて、CSV内のレコード検索や集計、編集操作を行うことができます。
この機能のおかげでデータの抽出やログの解析がめちゃくちゃスムーズになりました。
RBQL Consoleは、Visual Studio Code左下の[Query]をクリックするか、コマンドパレットを開いて「Rainbow CSV: RBQL」を選択することで起動します。
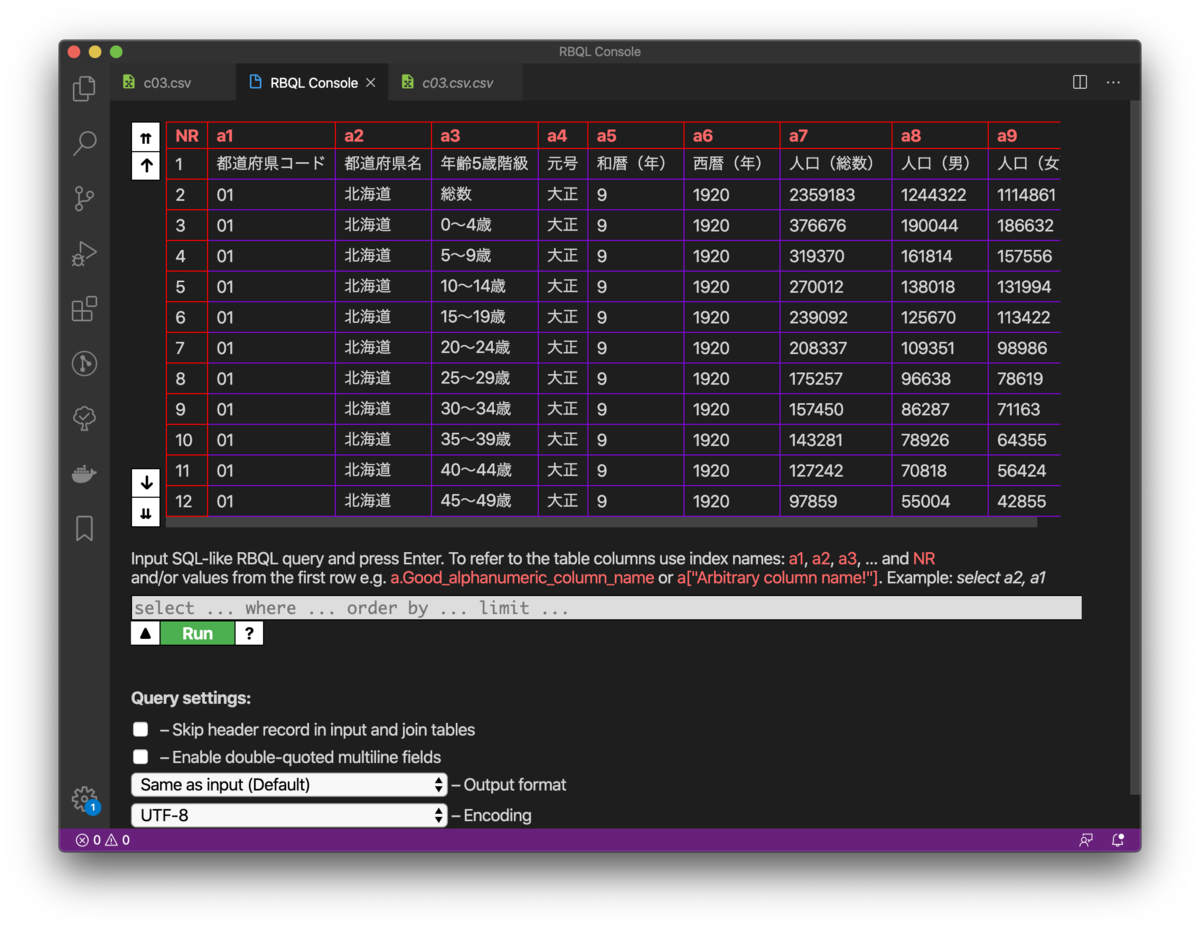
RBQLの例
select * where a1 == '01' (fromはなく、比較には=ではなく==を使います)
where
RBQLでは、利用する言語としてJavaScriptかPythonを指定できます。 どちらの言語を利用するかによって、クエリの書き方が変わるので注意が必要です。 (最初はこれでずいぶん悩みました)
例えば、次のクエリはPythonではエラーなく実行されますが、JavaScriptではエラーになります。
where a1 == '01' and a2 == '0〜4歳'
これはクエリが選択した言語(JavaScriptまたはPython)として解釈されるためです。
この解釈については前述のRBQLのページの「How RBQL works: Explanation」をご覧ください。
よって、JavaScriptでandやorを使いたい場合には、&&や||のように書く必要があります。
select * where a1 == '01' && a2 == '0〜4歳'
以下、特に断らない限りクエリはJavaScriptで記述します。
like
likeは関数として実装されています。
30代を抽出
select * where like(a['年齢5歳階級'], '3%')
関数の利用(JavaScript/Python)
関数を使ってデータを操作することも可能です。
select * where a['都道府県名'].indexOf('府') > -1
select
カラムは、a1, a2, ...のようにインデックスで指定したり、 a['都道府県コード'],a['都道府県名'],...というように、項目名(ヘッダテキスト)によって指定することができます。 項目名による指定では、"a["と入力するだけで候補が出てくるため、リストから選択することができます。
そのほかに、NRという行番号を表すカラムがあって、これを利用すると元のファイルから該当行を探す手間が省けるので便利です。
group by
select a['都道府県名'], a['西暦(年)'], sum(a['人口(総数)']) group by a['都道府県名'], a['西暦(年)'] where NR > 1
1行目はヘッダ文字列のためsumできないので除外しています。
order by
select * order by parseInt(a['人口(総数)'])
文字列として解釈されてしまうのを防ぐために、parseInt関数を用いています。
join
別のファイルとjoinすることもできます。 joinするファイルのカラムは、b1, b2, ... で指定します。
select * inner join ファイルパス on a1 == b1
update
update a['元号'] = 'T' where a['元号'] == '大正'
ちなみに、selectの結果やupdateの結果は別ファイルとして別タブに表示されるため、誤って元データを編集してしまうということもありません。 その結果に対してさらにRBQL Consoleを立ち上げてクエリを実行することも可能です。
また、copy backという機能が用意されており、これを使えば、編集結果を元データに書き戻すことも可能です。(Visual Studio Code左下のcopy backボタン)
おわりに
いかがでしたでしょうか?
RBQLを使えば、他のアプリで開くと重くなってしまうようなデータも比較的サクサク扱うことができますし、 CSVをCSVのまま取り扱うことができるのも良いですよね。 普段から起動してあるお気に入りのエディタ上で実行できるのも魅力です。
これでデータを扱う作業が捗ること間違いなしですね!
スタイルエッジ・LABOでは一緒に働く仲間を募集しております。 興味をお持ち頂けましたら是非とも下記をクリックしてください↓↓